根據上次得到的結果花了點時間看了一下整個系統大概分成兩個部分

alpr部分主要負責將圖片中的車牌框出來,並且將車牌中的每個字給切出來給ocr做辨識
目前alpr這邊測起來不修改參數設定的話其實都還抓的到,但是照片中的車牌必需要"正" 不能歪斜不然容易出現抓不到的情形
而tesseract的部分就會因為每個字體的不同而造成字的辨識出現錯誤,因此針對每個不同國家都需要重新去訓練出該國的資料庫來加強辨識效果
然而我們要進行資料庫的訓練的話,第一步就是要先收集資料,將車牌的資料收到至少有100台車子會比較好。
查詢了一下tesseract的training資料其實滿多的,
https://github.com/imonology/ImonCloud-Doc/wiki/openalpr
https://www.jianshu.com/p/34ffdb2cf082
https://www.itread01.com/content/1548144562.html
我這邊是使用train-ocr去訓練
看了上面的網站後大概知道要把0~9 a~z從圖中切出來並且做合併之後再送給train-ocr去訓練
好加在openalpr這邊有出了一個utility可以用 --openalpr-utils-classifychars
http://doc.openalpr.com/opensource.html
依照上面網站給的指示,其實我們可以在openalpr中重新建立一個國家的library,連同車牌大小、字的大小、比例都修改為符合我們真正的車牌狀況,並且訓練針對我們車牌字體的資料庫來增強準確性
但是因為我手上資料不足,所以沒辦法訓練台灣用的資料庫,所以先拿一些其他國家的來跑看看訓練流程!!
那就開始吧
1. 修改設定資料
在runtime_data/config/ 裡面加入一個新的國家檔,可從裡面復製一個出來後再修改內容
- plate_width_mm = [width of full plate in mm]
- plate_height_mm = [height of full plate in mm]
- char_width_mm = [width of a single character in mm]
- char_height_mm = [height of a single character in mm]
- char_whitespace_top_mm = [whitespace between the character and the top of the plate in mm]
- char_whitespace_bot_mm = [whitespace between the character and the bottom of the plate in mm]
- template_max_width_px = [maximum width of the plate before processing. Should be proportional to the plate dimensions]
- template_max_height_px = [maximum height of the plate before processing. Should be proportional to the plate dimensions]
- min_plate_size_width_px = [Minimum size of a plate region to consider it valid.]
- min_plate_size_height_px = [Minimum size of a plate region to consider it valid.]
- ocr_language = [name of the OCR language – typically just the letter l followed by your country code]
將上面的這些參數修改為目標國家的參數
2. 在終端機上輸入指令 openalpr-utils-classifychars [國家名] 待訓練照片路徑 輸出資料夾名稱
ex: openalpr-utils-classifychars mj ./image ./out
按下enter後可以看到下面的圖跑出來了
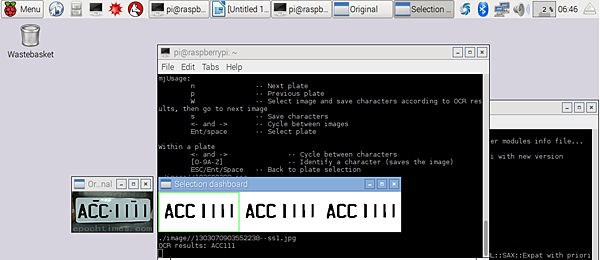
他上面有提到一些指令,n p w s 跟左右方向鍵都是用來控制圖片切割及存檔用的
這邊要注意一件事 一開始我發現我的鍵盤沒辦法正確的控制,後來google了一下才發現是因為key code設定不同造成的
因此如果有相同情形,請檢查classifychars.cpp 檔 先在289行那邊 std::cout << "key: " << (int) waitkey << std::endl; 加入這行
然後重新make一次,檢查看看每個的key code是多少,然後再到cpp檔案內一開始的define去修改設定值
const int ENTER_KEY_ONE = 10;
const int ENTER_KEY_TWO = 1048586;
const string SPACE = " ";
const int SPACE_KEY = 32;
const int ESCAPE_KEY = 27;
修改完後就可以開始切割圖檔了
- Press the “Enter” key and type the letter or number for each position that you wish to classify. Pressing “Space” will skip the character.
- Use the arrow keys and press “Space” to select how you wish to extract characters. The box you select will be highlighted in blue. For each plate, there may be good characters and bad characters; pick the best characters because significant imperfections may confuse the OCR.
- Press the “S” key to save each character as a separate file in your out folder.
- Press the “N” key to move to the next plate. Repeat this process until you’ve classified all the plates.
程式的使用說明可以參照網路上,簡單來說就是按空白鍵選那幾張圖是辨識好的,然後按enter鍵就會進到每個字元去辨識
如果有辨錯的(不是字確辨識為字)就按空白鍵跳過,如果選到的是正確的文字則輸入對應的字元,例如a 按完後會自動跳下一個
直到所有字都有被tag到
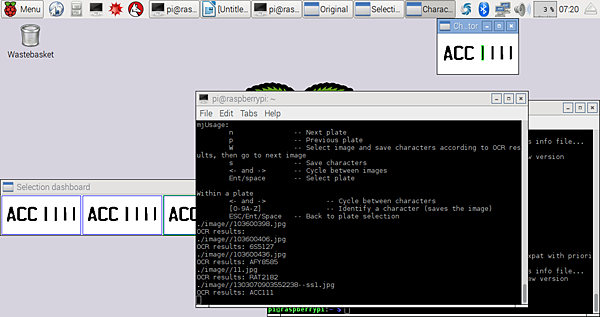
tag完就按下s 進行存檔
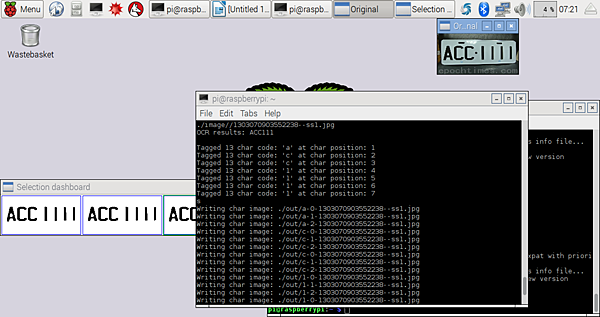
當然把所有的圖都切完後應該就可以得到如下這麼一大串的圖了~~
這邊再次說明一下,因為我沒有資料庫,所以沒辦法測試訓練完的結果
如果你手邊有資料庫願意讓我測試的,觀迎與我聯絡喔

接著使用 openalpr-utils-prepcharsfortraining 會幫你把所有切好的圖組合成一張圖,也就是
- combined.box
- combined.tif
最後,就是進行train-ocr了
Execute the “train.py” file. Type in your country code.
If all went well, you should have a new file named l[countrycode].traineddata. Copy this file into your runtime_directory (runtime_data/ocr/tessdata/), and it will be ready for OpenALPR to use.
訓練完就可以拿來用了!~~

 留言列表
留言列表

